【开源项目】最强图像生成模型Stable Diffusion 3.5的本地部署攻略
本文最后更新于 2024-12-10,文章内容可能已经过时。
前言
Stable Diffusion 3.5 是一款最新发布的先进图像生成模型,它基于深度学习技术,可以根据用户输入的文本提示生成高质量的图像。作为 Stable Diffusion 系列的最新版本,3.5 在图像生成的质量、速度和稳定性上都进行了显著优化,使得它在图像生成领域的表现更加卓越。
最令人激动的是,Stable Diffusion 3.5 可以在本地部署运行,这意味着用户可以在自己的计算机上直接生成图像,无需依赖云端服务,保障了数据隐私并提高了生成效率。
对于创作者、设计师、艺术家,甚至是开发者,Stable Diffusion 3.5 都提供了强大的工具和灵活的应用场景,无论是日常创作、游戏开发,还是广告设计,都能带来令人惊艳的视觉体验。
模型下载
版本区别
目前SD3.5提供三个不同版本,以满足不同用户需求。
这些模型的尺寸可高度定制,可在消费级硬件上运行,并且根据宽松的Stability AI 社区许可,可免费用于商业和非商业用途。

Stable Diffusion 3.5 Large:该基础型号拥有 80 亿个参数,质量卓越,响应迅速,是 Stable Diffusion 系列中最强大的型号。该型号非常适合 1 百万像素分辨率的专业用例。
Stable Diffusion 3.5 Large Turbo:稳定扩散 3.5 Large 的精简版仅需 4 个步骤即可生成高质量图像,且具有出色的快速依从性,速度比稳定扩散 3.5 Large 快得多。
Stable Diffusion 3.5 Medium: 该模型拥有 25 亿个参数,采用改进的 MMDiT-X 架构和训练方法,可在消费级硬件上“开箱即用”,在质量和定制易用性之间取得平衡。它能够生成分辨率在 0.25 到 2 百万像素之间的图像。
这些模型的尺寸可高度定制,可在消费级硬件上运行,并且根据宽松的Stability AI 社区许可,可免费用于商业和非商业用途。
ComfyUI 软件和汉化包
安装 ComfyUI
如果你是新手,你必须在你的机器上安装ComfyUI,老用户需要选择”Update ComfyUI”和”Update All”来更新ComfyUI。
ComfyUI 是一个基于 Stable Diffusion 模型的用户界面(UI)工具,旨在简化图像生成过程,提供更加直观和便捷的操作体验。
ComfyUI 使用户能够轻松与 Stable Diffusion 进行交互,生成高质量的图像,特别适合那些不熟悉命令行操作的用户,或者希望通过图形界面快速实现图像创作的用户。
最新 ComfyUI 已经支持最新的稳定版 Stable Diffusion 3.5!!!
ComfyOrg 相关Blog:blog.comfy.org/sd3-5-comfyui/
ComfyUI 项目地址:【点击进入】
在此项目的发布页下载最新的 ComfyUI 到本地,之后随便解压到一个路径就可以。
可以参考文章【在 PC 上轻松安装 Comfy UI (Windows/Mac/Linux)】
安装汉化包
由于默认下载的 ComfyUI 是英文的,如果看的不舒服的话可以下载汉化包进行补充;
ComfyUI 汉化包:【点击进入】
进入项目主页后,将项目的整个下载下来,一般情况下,会得到一个ZIP 文件,最后将整个 ZIP 包整体解压放到ComfyUI\custom_nodes 目录中即可完成;
安装完 ComfyUI 之后,额外的可以安装一个 ComfyUI Manager 帮助您安装和管理自定义节点。
移动到”ComfyUI/custom_nodes”文件夹,在文件夹路径位置并输入”cmd”打开命令提示符,输入下面的命令进行安装。
.\python_embeded\python.exe -s -m pip install gitpython
.\python_embeded\python.exe -c "import git; git.Repo.clone_from('https://github.com/ltdrdata/ComfyUI-Manager', './ComfyUI/custom_nodes/ComfyUI-Manager')"StabilityAI版:Stable Diffusion 3.5
拥有强大GPU并且只想使用原始模型的用户可以使用这个官方版本。
Step1:注册 Hugging Face 账号
在 Hugging Face 开源社区下载文件必须要注册自己的账号;
Step2:下载工程文件和模型文件
进入 Stability AI 模型界面,点击要下载的模型,以 Stable Diffusion 3.5 Large 模型权重为例,进入 ”Files and versions“ 选项,如下图所示,下载 json 和 safetensors 结尾的文件即可,其他两个模型的下载方法基本一致。
首次下载时,你需要接受他们的许可和协议才能访问他们的存储库。

也可以直接点击下面的链接快速进入相应模型界面;
Stable Diffusion 3.5 Large 【点击下载】推荐16G以上显存
Stable Diffusion 3.5 Large Turbo 【点击下载】 推荐8G以上显存
Stable Diffusion 3.5 Medium【点击下载】推荐低显存
GGUF量化版:Stable Diffusion 3.5
除过前面的官方版本,如果电脑的显卡实在有限,可以考虑下面的量化版本。
量化版本在不影响大量图像像素的情况下产生相当好的质量。这对于配备M1/M2芯片的Mac机器来说非常棒[^1]。
它消耗较低的GPU并且渲染时间更短。特别是GGUF Loader在GPU上工作以提高VRAM的整体性能。使用T5文本编码器来降低VRAM功耗。
1. 移动到”ComfyUI/custom_nodes”文件夹。导航到文件夹路径位置并输入”cmd”打开命令提示符。
GGUF Flux用户如果已经安装了这个存储库则不需要重新安装,只需更新即可。移动到”ComfyUI/custom_nodes/ComfyUI-GGUF”文件夹并在命令提示符中输入”git pull”,下载步骤4中提到的SD 3.5量化模型权重并保存到相应文件夹。
2. 然后通过复制并粘贴以下内容到命令提示符来安装和克隆存储库:
git clone https://github.com/city96/ComfyUI-GGUF.git 3. 对于便携式用户,移动到”ComfyUI_windows_portable”文件夹,到文件夹路径位置并输入”cmd”打开命令提示符。
使用此命令安装依赖项:
git clone https://github.com/city96/ComfyUI-GGUF ComfyUI/custom\_nodes/ComfyUI-GGUF
.\\python\_embeded\\python.exe -s -m pip install -r .\\ComfyUI\\custom\_nodes\\ComfyUI-GGUF\\requirements.txt4. 相应存储库中列出了多个模型。下载以下任一预量化模型:
将它们保存到”ComfyUI/models/unet”目录。这里,所有的clip模型都已经由CLIP loader处理,所以,不需要下载这个。
但是,如果你想要的话,你可以根据你的GGUF(t5_v1.1-xxl GGUF)模型从Hugging Face下载并保存到”ComfyUI/models/clip”文件夹。
5. 然后重启并刷新ComfyUI使其生效。
部署流程
本文下载的是 StabilityAI 的 Stable Diffusion 3.5 Large Turbo 模型,后面的演示都是基于此展开的。
Step1:放置模型文件
将前面第一步下载的 Stable Diffusion 3.5 Large、Stable Diffusion 3.5 Large Turbo 或 Stable Diffusion 3.5 Medium 放到您的 models/checkpoint 文件夹;
Step2:下载工程文件和模型文件
将clip_g.safetensors、clip_l.safetensors和t5xxl_fp16.safetensors下载到 models/clip 文件夹(您可能已经下载了它们);
注意:低显存请选择量化版 t5xxl_fp8_e4m3fn.safetensors 或 t5xxl_fp8_e4m3fn_scaled.safetensors
Step3:拖入工作流并完成
有显卡的话最好直接运行 ComfyUI 解压包里的 run_nvidia_gpu.bat 文件,这里速度会快点,并在设置里切换语言为简体中文;

进入软件的 Web UI 界面后,首先拖入工作流程文件,即前面下载的 json 文件;然后选择下载的对应模型和 CLIP 文件,设置好图片提示词,以及输出的图片尺寸和数量,如下图所示进行操作;最后点击“执行队列”按钮,等待图像生成完成[^2]:。

当然除了在GitHub 上下载,你可以直接在线体验文生图片的效果:
模型测试
提示词
示例 1
1 chinese girl,solo,flower,dress,black dress,black hair,holding,strapless,bare shoulders,holding flower,rose,watermark,strapless dress,parted lips,earrings,pink flower,jewelry,dark,bare arms
示例 2
(RAW photo, best quality), (realistic, photo-realistic:1.3), masterpiece, an extremely delicate and beautiful, extremely detailed, CG, unity, 8k, amazing, finely detail, ultra-detailed, highres, absurdres, soft light, (black hair, short hair, curly hair, messy hair, bangs), beautiful detailed girl, detailed fingers, extremely detailed eyes and face, beautiful detailed nose, beautiful detailed eyes, (light on face), looking at viewer, (closed mouth:1.2), 1girl, cute, young, mature face, pale skin, (half body:1.3, sitting), (medium breasts), realistic face, realistic body, beautiful detailed thigh, (ulzzang-6500-v1.1:0.6), <lora:koreandolllikeness_v20:0.5>, (white shirt, collared shirt, lace, black miniskirt, pantyhose, detached sleeves, bowtie), <lora:zhengyingshan6:0.6>, (semi smile:1.3), (aegyo sal:1), (kpop idol:1), relaxed,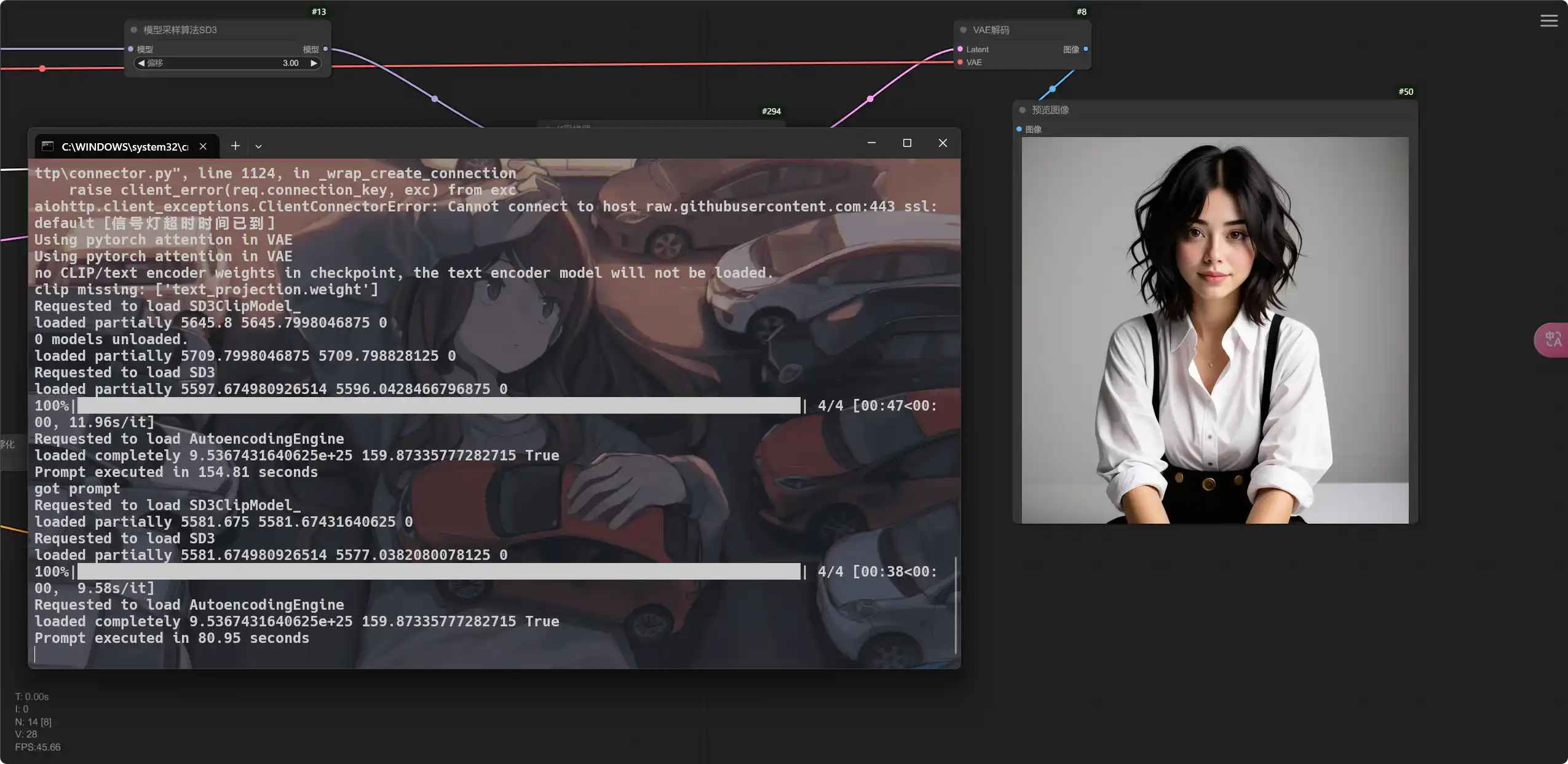
总结
Stable Diffusion 3.5 版本在可定制性、性能和输出多样性方面表现出色,成为市场上最易访问且功能强大的图像生成模型之一。用户可以轻松微调模型,以满足特定创作需求,或者根据个性化工作流程进行灵活的应用开发。经过精心优化的性能,使其能够在标准消费级硬件上也能高效运行,尤其是在 Stable Diffusion 3.5 Medium 和 Large Turbo 版本中,性能表现尤为突出。此外,该版本还具备强大的多样化输出能力,能够生成展现不同肤色、特征的人物图像,帮助用户创作出更具包容性的视觉作品,而这一切都无需依赖复杂的提示设置,从而大大提高了创作的便捷性和灵活性[^3]。
参考文章
[^1]:【最新】Stable Diffusion 3.5安装教程:ComfyUI平台完整指南
[^2]:https://www.bilibili.com/opus/1008612115319095302